
Gran parte del dibattito sull’infrastruttura per l’IA inizia con un modello di IA in esecuzione su GPU. Tuttavia, in pratica, i requisiti dell’infrastruttura per l’IA sono sempre più determinati dal flusso di lavoro che ruota attorno al modello.
I sistemi di intelligenza artificiale agentica non si limitano a rispondere a un comando. Interpretano l’intento, recuperano il contesto, pianificano i passi successivi, richiamano strumenti, applicano policy, eseguono codice in ambiente di test, effettuano transazioni, osservano i risultati e restituiscono un output.
Ogni passaggio rappresenta un carico di lavoro diverso, e tutti insieme contribuiscono a creare un flusso di lavoro variegato. Alcuni richiedono un’elevata densità di core. Altri traggono vantaggio da un’alta frequenza e da una latenza prevedibile. Altri ancora dipendono dalla capacità di memoria, dall’I/O, dalla località dei dati, dall’efficienza energetica o dalla capacità di ospitare molti servizi simultanei.
Con la crescente diffusione dell’IA agentiva, i team infrastrutturali necessitano di più di un singolo profilo di calcolo. I CIO e i responsabili delle decisioni aziendali hanno bisogno di un portafoglio di CPU adatte all’intero flusso di lavoro agentivo.
Il portfolio di CPU server AMD EPYC™ è posizionato idealmente per svolgere questi ruoli, non come un’unica CPU in grado di offrire una soluzione universale, ma come un componente unico per i molteplici carichi di lavoro dell’IA agentiva. (Per saperne di più sull’importanza delle CPU nell’IA agentiva, leggi il mio precedente articolo, ” L’IA agentiva cambia l’equazione CPU/GPU “).
All’interno del flusso di lavoro di Agentic AI
Quando un agente si assume un compito, scompone l’obiettivo in fasi e le esegue una per una, spesso tornando sui propri passi più volte prima di completarle. In una sequenza tipica, la richiesta raggiunge un gateway dove vengono applicate le policy. Un livello di pianificazione, che spesso esegue modelli di intelligenza artificiale più piccoli, determina come instradare il compito. L’agente interroga quindi i database, attiva un cluster GPU per un ragionamento più approfondito, esegue strumenti basati su tale ragionamento, verifica l’output e decide se ripetere il ciclo o terminare.
Questo spiega perché l’IA agentiva dovrebbe essere vista come un flusso di lavoro end-to-end, non come un singolo carico di lavoro. La giusta strategia infrastrutturale inizia mappando ogni flusso di lavoro e assegnandogli poi le risorse CPU appropriate.
AMD si concentra su ogni fase del flusso di lavoro: CPU EPYC per il calcolo ad alta frequenza e ad alta densità, acceleratori AMD Instinct™ per l’inferenza e l’addestramento dell’IA e la rete Pensando™ per facilitare il trasferimento prevedibile dei dati.
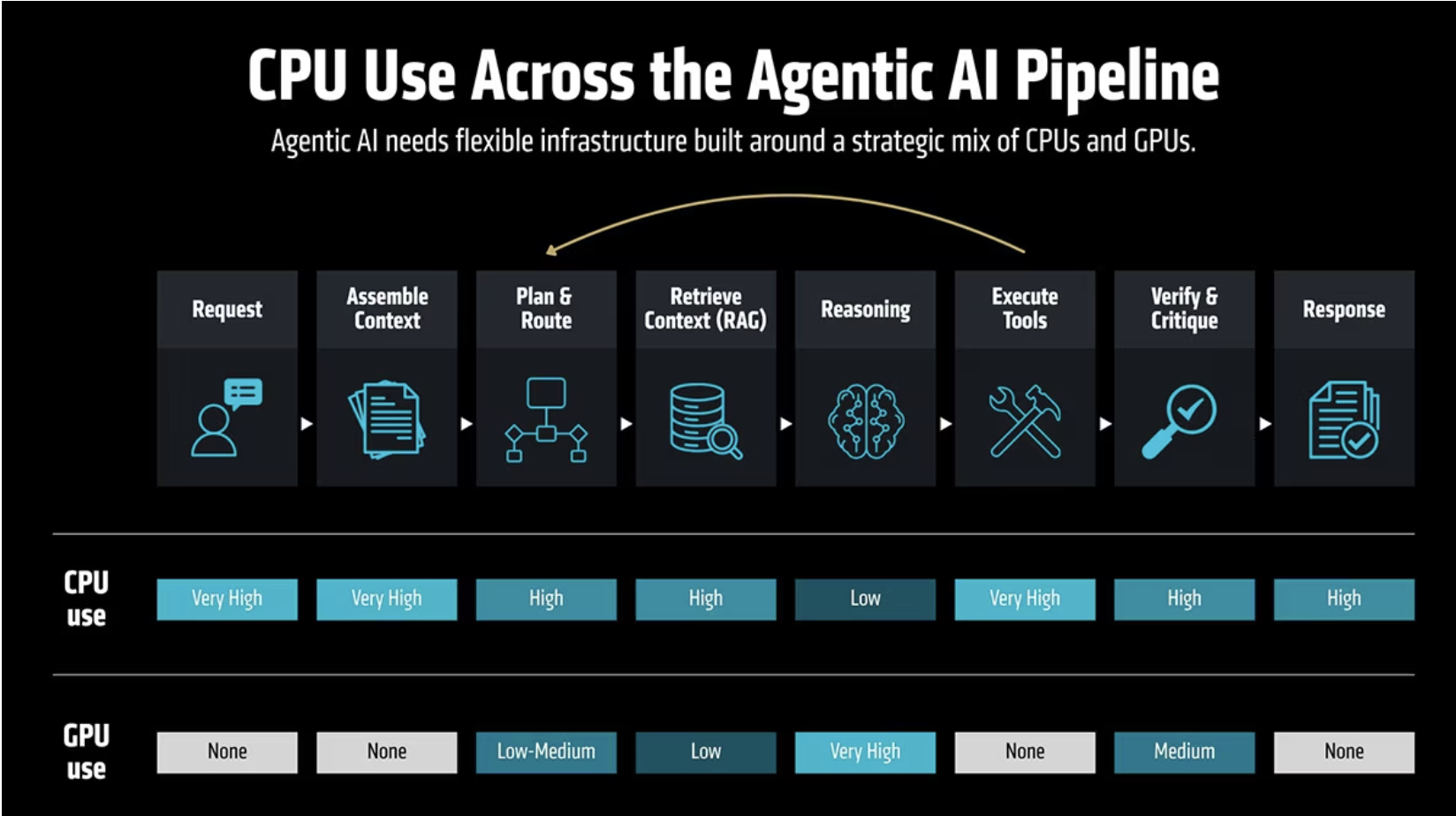
Dove la latenza conta, dove la velocità di trasmissione è fondamentale e dove hai bisogno di entrambe
Ogni fase del flusso di lavoro ha esigenze diverse, ed è per questo che abbiamo progettato il portfolio AMD EPYC attorno a una combinazione di profili.
- Orchestrazione di agenti, esecuzione in ambiente sandbox, chiamate a strumenti: quando è necessario che molti agenti eseguano simultaneamente codice sandbox (ad esempio, Python), chiamino API o interroghino database, la densità dei core può essere più importante della frequenza di clock. Le nostre CPU server AMD EPYC™ di quinta generazione offrono fino a 192 core e 384 thread con multithreading simultaneo. Entro la fine dell’anno, i nostri processori EPYC di nuova generazione, nome in codice “Venice”, porteranno questi valori a 256 core e 512 thread.
- Esecuzione di strumenti su applicazioni aziendali: la possibilità di richiamare strumenti o applicazioni aziendali rende gli agenti utili. Le CPU con un’ampia gamma di core, combinata con prestazioni elevate, gestiscono il volume e la varietà delle richieste in entrata. La famiglia di processori AMD EPYC™ 9005 offre questo equilibrio con un numero di core da 8 a 192 e una larghezza di banda della memoria fino a 640 GB/s, con “Venice” che estende il numero di core/thread di 1,3 volte e la larghezza di banda della memoria di 2,5 volte.
- Ragionamento con inferenza: per fornire agli agenti di intelligenza le informazioni necessarie per svolgere il proprio lavoro, questi si affidano all’inferenza. I modelli linguistici di grandi dimensioni vengono eseguiti prevalentemente su GPU, con una CPU host che mantiene le GPU pienamente utilizzate. Per mantenere gli acceleratori occupati, le CPU dei nodi host spesso beneficiano di elevate prestazioni per core, alte frequenze e del giusto equilibrio tra core (a volte ne servono meno di quanto si possa pensare), larghezza di banda della memoria, I/O e rete. La giusta combinazione nella CPU del nodo host può alimentare i cluster di GPU con istruzioni in modo che ciascun cluster produca il maggior numero possibile di token. Il processore AMD EPYC™ 9575F offre queste elevate prestazioni single-core con 64 core in grado di funzionare fino a 5 GHz. “Venice” amplierà ulteriormente l’offerta di alte frequenze delle CPU EPYC.
La sfida dell’eredità
Nelle conversazioni con i clienti aziendali, emergono un paio di schemi ricorrenti.
Innanzitutto, molti standardizzano i propri acquisti di infrastrutture CPU basandosi su specifiche obsolete, come l’utilizzo di CPU a 16 e 32 core. I flussi di lavoro agentivi richiedono un numero maggiore di core per alcune fasi, frequenze più elevate per altre, e i clienti necessitano della flessibilità di configurare entrambe le opzioni. È necessario abbandonare l’approccio basato su un unico standard CPU e adottare un portfolio di CPU adattato al flusso di lavoro agentivo.
In secondo luogo, si verifica un effetto moltiplicatore sulle applicazioni aziendali e sui server di inferenza, dovuto al crescente utilizzo degli agenti da parte dell’infrastruttura IT esistente. Una volta che i dipendenti hanno la possibilità di creare e implementare i propri agenti, l’adozione di questi ultimi cresce rapidamente. I team di pianificazione IT dovrebbero chiedersi cosa succede alla propria infrastruttura – ad esempio database, piattaforme per la pianificazione delle risorse aziendali e la gestione delle relazioni con i clienti, business intelligence, gestione delle identità e server di inferenza – quando l’utilizzo da parte degli agenti aumenta drasticamente.
La domanda per i CIO
L’IA agentiva sta cambiando il modo in cui le aziende dimensionano le proprie infrastrutture. I responsabili IT che la considerano un problema monolitico – una singola strategia basata su GPU o una CPU universale – probabilmente incontreranno delle difficoltà. Ma con la proliferazione degli agenti, coloro che pianificano un flusso di lavoro end-to-end diversificato con esigenze di calcolo differenti in ogni fase possono scalare in modo più efficiente.
La domanda che vale la pena porsi non è di quante CPU o GPU abbia bisogno la tua azienda per l’IA agentiva, ma se l’infrastruttura sia adeguata al funzionamento dell’IA agentiva nelle sue numerose fasi e ai diversi carichi di lavoro. Se mappi queste fasi fin dalle prime fasi e scegli il profilo di calcolo giusto per ciascuna, la tua azienda sarà ben posizionata per garantire velocità ed efficienza man mano che si espande.