
Di Pavel Minarik, CTO di Flowmon Networks
I dati di flusso, come NetFlow e IPFIX, sono notoriamente utilizzati dai fornitori di telecomunicazioni per la fatturazione dei servizi, la pianificazione della capacità di rete e la protezione contro i DDoS. Solo recentemente le imprese hanno iniziato a esplorarne il potenziale per il networking e la sicurezza. Ancora oggi, alcuni miti in proposito impediscono un’adozione più rapida della tecnologia di flusso e la maggior parte di essi si basa su una mancanza di informazioni o di dettagli fraintesi. Ecco i quattro principali miti su NetFlow.
Mito 1: i dati di flusso sono campionati e molto imprecisi
Questo problema sussiste per gli standard sFlow o NetFlow Lite supportati su dispositivi obsoleti a volte utilizzati dalle PMI.
Al contrario, tutti i principali fornitori di apparecchiature di rete aziendali forniscono oggi router e switch in grado di esportare statistiche sul traffico non campionato e molto accurato.
Tutti i principali fornitori di firewall consentono l’esportazione del flusso, incluse le piattaforme virtualizzate. L’accesso ai dati di flusso non campionati è ormai la regola, consentendo quindi misurazioni accurate e di alta precisione.
Dati di flusso completi non campionati consentono la visualizzazione del traffico di rete tra i server, mostrando l’utilizzo di singoli collegamenti uplink in varie località.
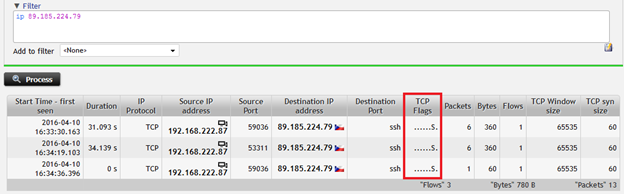
Un altro utilizzo importante è costituto dalla risoluzione dei problemi di rete. Un utente, ad esempio, potrebbe avere problemi durante la connessione a un server tramite un servizio SSH: con i dati di flusso si può confermare che non vi è stata risposta dal server e quindi escludere molte potenziali cause, come il tempo di inattività del server o della rete o una configurazione scadente.
È possibile restringere il campo delle cause al mancato funzionamento del servizio o alla comunicazione bloccata da un firewall o altro dispositivo. Questo processo riduce notevolmente il Mean-Time-To-Resolve (MTTR).
Mito 2: il flusso è limitato alla visibilità L3 / L4
Originariamente i dati di flusso erano limitati ai livelli 3 e 4, ma oggi non è più così perché descrivono un singolo flusso di pacchetti nella rete utilizzando i bit di identificazione 5-tuple, che mostrano l’indirizzo IP di origine e destinazione, la porta di origine, la porta di destinazione e il protocollo di comunicazione.
Tali pacchetti vengono aggregati in un record di flusso che mostra così la quantità di dati trasferiti, il numero di pacchetti e altre informazioni provenienti dal livello di rete e trasporto.
Per ottenere dati ancora più utili, cinque anni fa Flowmon ha sviluppato dati di flusso arricchiti con informazioni dal livello dell’applicazione e questo concetto è stato recentemente adottato anche da molti altri vendor. Quindi è ora possibile avere una visione dettagliata dei protocolli applicativi come HTTP, DNS e DHCP per la risoluzione dei problemi.
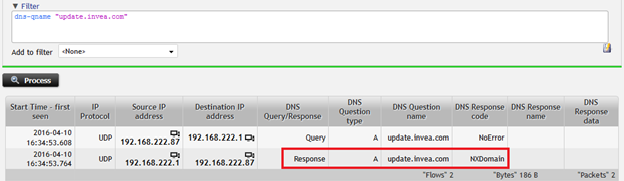
In un altro esempio, un utente potrebbe avere un servizio che non risponde. Analizzando i dati di flusso tradizionali, un tecnico può visualizzare lo schema del traffico e i dettagli sulle singole connessioni stabilite dal computer dell’utente, ma utilizzando l’analisi standard del flusso non è possibile vedere alcun traffico verso il servizio.
Con la visibilità estesa offerta da un flusso dati arricchito, il tecnico può facilmente risolvere il problema: potrebbe risultare che il nome del servizio richiesto non è configurato correttamente in DNS e restituisce “NXDOMAIN”, indicando che il nome di dominio richiesto non esiste e non è possibile fornire l’indirizzo IP corrispondente, e in questo caso non viene stabilita alcuna sessione, da cui il problema.
Mito 3: i dati di flusso non soddisfano le metriche relative alle prestazioni della rete
Oltre alla risoluzione dei problemi, un’altra considerazione importante è il monitoraggio delle prestazioni della rete.
Il monitoraggio della rete non è più dominio unico dei tool di cattura dei pacchetti; le metriche possono essere facilmente estratte dai dati a pacchetto ed esportate come parte delle statistiche di flusso.
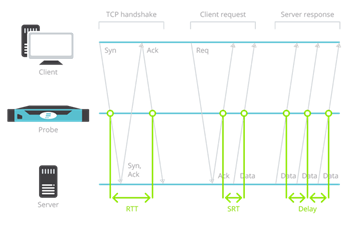
Indicatori di prestazioni come RTT (round trip time), SRT (server response time), jitter o numero di ritrasmissioni, sono disponibili in modo trasparente per tutto il traffico di rete, indipendentemente dal protocollo dell’applicazione. Ora è possibile misurare le prestazioni di tutte le applicazioni, gestite in locale, in un cloud privato o pubblico. Per capire meglio come vengono estratti questi parametri, qui una sonda Flowmon fornisce metriche RTT, SRT e jitter / delay per il monitoraggio delle prestazioni:
Mito 4: Flow non è uno strumento completo per Network Performance and Diagnostics (NPMD)
Secondo Gartner, gli strumenti NPMD dovrebbero fornire metriche prestazionali sfruttando i dati completi dei pacchetti e analizzare i problemi di rete analizzando le tracce complete dei pacchetti stessi.
Invece di una soluzione di acquisizione di pacchetti, i dati di flusso arricchiti forniscono statistiche sul traffico accurate, visibilità su L7 (protocolli applicativi) e metriche sulle prestazioni di rete, quindi sono pienamente in grado di eseguire le analisi NPMD.
In realtà, con l’aumento del traffico crittografato, ambienti sempre più eterogenei e un aumento delle velocità di rete, è inevitabile che il flusso diventerà un approccio predominante in NPMD. La tendenza verso una maggiore larghezza di banda costituisce una sfida molto difficile per le soluzioni legacy basate sui pacchetti.
Si consideri che un backbone di rete con capacità 10G richiede fino a 108 TB di storage per tracciare il traffico di rete per 24 ore. Si tratta di una quantità enorme di dati da raccogliere, archiviare e analizzare, rendendo il processo estremamente costoso, se non impossibile.
In alternativa, con il flusso di dati arricchito, è sufficiente una piccola parte dei dati. I dati di flusso nella stessa situazione richiedono circa 250 GB di spazio di archiviazione, consentendo 30 giorni di cronologia su un supporto dotato di memoria da 8 TB. Pertanto, sfruttando i dati di flusso, è possibile ottimizzare le operazioni di rete e risolvere i problemi relativi con una frazione delle risorse.
Per risolvere un problema specifico su un protocollo applicativo non supportato, in cui non vi è visibilità nei dati di flusso, è possibile utilizzare una sonda per accedere ai dati a pacchetto completi. Quindi, invece di estrarre tutti i metadati dai pacchetti, si richiede semplicemente alla sonda di eseguire un’attività di acquisizione dei pacchetti. Questo compito sarà limitato nel tempo e strettamente focalizzato sulla registrazione dei pacchetti relativi a un’indagine. L’acquisizione selettiva di pacchetti su richiesta è facile da gestire anche in un ambiente multi-10G, senza la necessità di un grande spazio di archiviazione.
Dati di flusso per dinamiche future
La tecnologia dei dati di flusso arricchiti è notevolmente maturata con granularità necessaria per la risoluzione degli incidenti di rete, problemi di configurazione, pianificazione della capacità e altro. Rispetto agli strumenti di acquisizione di pacchetti continui, le soluzioni di flusso dati arricchiti offrono un’ampia scalabilità, flessibilità e facilità d’uso. Di conseguenza, i dati di flusso fanno risparmiare tempo, riducono l’MTTR e riducono il costo totale delle operazioni di rete. Inoltre, forniscono anche l’analisi delle prestazioni della rete e il rilevamento dei comportamenti degli attaccanti attivi, compresi gli indicatori di compromissione, movimento laterale (Network Lateral Movement) e APT.
Le organizzazioni hanno gradualmente abbandonato la tecnologia di acquisizione dei pacchetti e l’hanno sostituita con il flusso. L’adozione di cloud, IoT, SDN e l’onnipresente esplosione della larghezza di banda continueranno a sviluppare ulteriormente questa tendenza.